
Machine Learning, Uczenie Maszynowe to metoda analizy danych, która polega na automatycznym tworzeniu modeli analitycznych.
W ramach Machine Learningu przyjmuje się, że algorytmy potrafią się samodzielnie uczyć.
Przez naukę należy przede wszystkim rozumieć identyfikację wzorców oraz podejmowanie decyzji z ograniczoną interwencją człowieka.
Choć powyższe definicje mogą wydać się do pewnego stopnia niekomunikatywne, to po przeczytaniu niniejszego artykułu wszystko, co w nich abstrakcyjne nabierze o wiele bardziej konkretnego charakteru.
Czym jest Machine Learning? Gdzie znajduje zastosowanie Uczenie Maszynowe?
Dlaczego Machine Learning jest tak istotny? Jakie są biznesowe uzasadnienie dla wykorzystania algorytmów Uczenia Maszynowego?
Odpowiedzi na te i kilka innych pytań znajdziecie w poniższym artykule, do którego czytania serdecznie, jak zwykle, zapraszamy.
Uczenie Maszynowe - co to jest?
Na pytania, czym jest Machine Learning, co to jest Machine Learning, co to jest Uczenie Maszynowe, jak działa Uczenie Maszynowe najprościej odpowiedzieć, że Uczenie Maszynowe jest częścią sztucznej inteligencji (Artificial Intelligence).
Uczenie Maszynowe zorientowane jest na udostępnienie danych systemom, dzięki czemu mają one możliwość uczenia się, doskonalenia w sposób automatyczny oraz samodzielny.
First things first!
Dlatego właśnie na początek zacznijmy od uporządkowania nieco terminologii, jakiej będziemy tutaj używali. Uczenie maszynowe a sztuczna inteligencja (Machine Learning vs AI) - tak można zakreślić pierwszy problem.
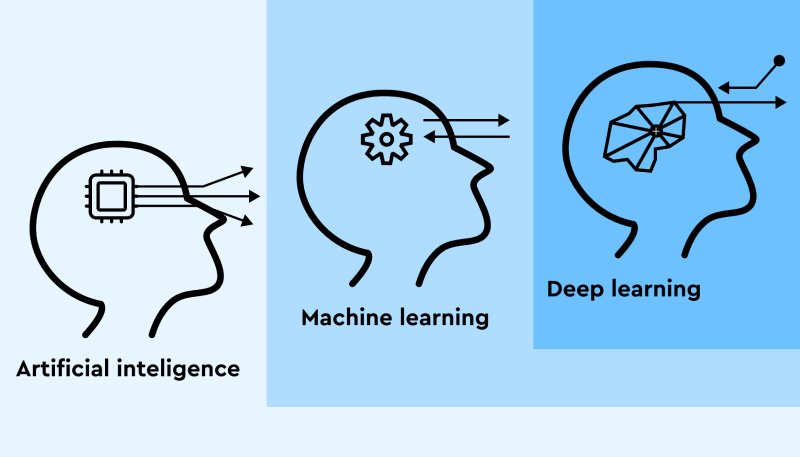
Otóż, głębokie Uczenie Maszynowe (Machine Learning) to nie to samo co sztuczna inteligencja (Artificial Intelligence - AI).
Pojęcia nie są synonimami i nie można ich używać wymiennie, choć czasami w literaturze przedmiotu takich synonimizacji się dokonuje.
Dbając o ścisłość trzeba powiedzieć, że relacja zawierania się pojęć wygląda następująco:
- AI - Artificial Intelligence - Sztuczna Inteligencja (pojęcie najszersze, zawierające w sobie pojęcia o węższym zakresie)
- ML - Machine Learning - Uczenie Maszynowe (pojęcie węższe, zawierające się w AI, ale się do niej nie sprowadzające)
- DL - Deep Learning - Uczenie Głębokie (pojęcie o najwęższym zakresie, stanowiące część Machine Learningu oraz Artificial Intelligence).
Czym te pojęcia, dziedziny wiedzy, technologie się różnią?
Sztuczna Inteligencja w najogólniejszym sensie jest nauką o naśladowaniu ludzkich zdolności uczenia, sposobu uczenia, przetwarzania informacji, poznawania, kategoryzowania danych oraz rozwiązywania problemów.
Jak czytamy w artykule pt. „Artificial intelligence (AI) vs machine learning (ML)”, dzięki AI system komputerowy wykorzystuje matematykę i logikę do symulowania sposobu rozumowania, jaki ludzie używają do uczenia się.
Chodzi o nieustanne włączanie nowych informacji oraz podejmowanie, dzięki ustawicznej nauce, lepszych, bardziej trafnych, korzystnych, skutecznych decyzji.
Uczenie Maszynowe jest specyficznym podzbiorem Sztucznej Inteligencji. Jego celem jest tworzenie algorytmów, które mają nauczyć maszynę uczenia się.
Albo mówiąc w nieco inny jeszcze sposób, Machine Learning jest specyficzną aplikacją Artificial Intelligence.
Jest procesem tworzenia, wykorzystywania matematycznych modeli danych, które mają usamodzielniać i uniezależniać algorytmy od konieczności wydawania bezpośrednich instrukcji przez człowieka.
Zatem, celem ML jest nauka jak najbardziej samodzielna i dążąca do doskonalenia w oparciu o zdobyte uprzednio doświadczenie.
Celem specjalistów rozwijających technologie AI jest stworzenie algorytmów, które pozwalają wykonywać zadania w sposób jak najbardziej bliski specyfice myślenia człowieka, której kluczowym elementem jest inteligencja, inteligentność.
Ideą, która stoi za Uczeniem Maszynowym jest przekonanie, że maszynom należy zapewnić dostęp do danych i pozwolić im uczyć się samodzielnie.
Konkluzję powyższych rozważań niech stanowi zdanie z artykułu pt. „How machine learning works”, opublikowanego na blogu Algorithmia.com.
A brzmi ono następująco: Prawie każde zadanie, które można wykonać za pomocą wzorca zdefiniowanego na podstawie danych lub zestawu reguł, można zautomatyzować za pomocą uczenia maszynowego.
Trzeba przyznać, że brzmi to bardzo obiecująco, przede wszystkim z biznesowego punktu widzenia. Ale także z punktu widzenia potrzeb użytkowników produktów cyfrowych.
W praktyce oznacza to możliwość automatyzacji wielu procesów, które dotychczas wykonywane musiały być przez odpowiednio edukowanych, przygotowanych i częstokroć zmęczonych, niezaangażowanych, rozkojarzonych ludzi.
Choć aspekt psychologiczny może nie wydawać się tutaj najistotniejszy, ale warto o nim wspomnieć, bowiem rozwiązania oparte na Machine Learningu są wolne od typowo ludzkich przypadłości i niedoskonałości.
Co oczywiście w wielu wypadkach, kontekstach, procesach, celach, potrzebach ma znaczenie niebagatelne.
Wpływa bowiem na większą wydajność, ekonomiczność, konkurencyjność organizacji oraz na poziom satysfakcji jej klientów, użytkowników.
Za przykład niech posłuży prosty asystent klienta na stronie firmy kurierskiej, który 24h na dobę, 7 dni w tygodniu, przez cały rok służy pomocą dowolnej ilości klientów, odpowiadając na ich pytania (bardzo często typowe, powtarzalne), nigdy nie odczuwając znużenia, frustracji, czy braku sensu.
Algorytmy wykorzystywane w Machine Learningu już teraz są w stanie skutecznie wyjść naprzeciw wielu typowym potrzebom klientów i - jak w naszym powyższym przykładzie - udzielić odpowiedzi na wiele często zadawanych pytań.
Jakie są metody Uczenia Maszynowego?
W ramach Machine Learningu wykorzystywane są różne metody, ale cztery z nich stosowane są najczęściej. A są nimi:
- uczenie maszynowe nadzorowane (Supervised Machine Learning)
- uczenie maszynowe nienadzorowane (Unsupervised Machine Learning)
- uczenie maszynowe częściowo nadzorowane (Semi-Supervised Learning)
- uczenie maszynowe wzmocnione (Reinforcement Learning).
Czym różnią się od siebie? Odwołajmy się do definicji zaprezentowanych w artykule pt. „What is machine learning?”, a opublikowanym na blogu firmy IBM, która ma znaczny wkład w rozwój Machine Learningu.
Uczenie nadzorowane polega na użyciu etykietowanych (oznakowanych) zbiorów danych do trenowania algorytmów, które klasyfikują dane lub przewidują wyniki.
W miarę jak dane wejściowe są wprowadzane do modelu, dostosowuje on swoje wagi, aż model zostanie odpowiednio dopasowany.
Odbywa się to w ramach procesu walidacji krzyżowej, która pozwala uniknąć przeuczenia (Overfitting) lub niedouczenia (Underfitting) modelu.
A mówiąc nieco prostszym językiem, w uczeniu nadzorowanym dane są oznaczone etykietami, aby dokładnie powiedzieć maszynie, jakich wzorców powinna szukać.
Uczenie nienadzorowane wykorzystuje algorytmy uczenia maszynowego do analizy i grupowania nieoznakowanych zbiorów danych.
Algorytmy te odkrywają ukryte wzorce lub grupy danych bez potrzeby interwencji człowieka.
Uczenie nienadzorowane jest używane do odkrywania podobieństw i różnic w informacjach, dzięki czemu jest to idealne rozwiązanie do analizy danych eksploracyjnych, strategii sprzedaży krzyżowej, segmentacji klientów, rozpoznawania obrazów i wzorców.
Nienadzorowane algorytmy uczenia maszynowego są używane, gdy dane wykorzystywane do uczenia nie są sklasyfikowane ani oznaczone.
Uczenie nienadzorowane bada, w jaki sposób systemy mogą wywnioskować funkcję opisującą ukrytą strukturę z danych nieoznaczonych.
System nie określa właściwych danych wyjściowych, ale eksploruje dane i może wyciągać wnioski z zestawów danych w celu opisania ukrytych struktur z danych nieoznaczonych.
Mówiąc nieco jeszcze innym językiem, w uczeniu nienadzorowanym algorytm próbuje nauczyć się pewnej nieodłącznej struktury danych za pomocą tylko nieoznaczonych przykładów.
Dane nie mają etykiet a zadaniem maszyny jest po prostu odnalezienie wszelkich wzorów, jakie może znaleźć.
Uczenie częściowo nadzorowane jest próbą pogodzenia zalet obu powyższych metod - nauki nadzorowanej oraz nienadzorowanej.
W toku nauki algorytm wykorzystuje mniejszy zestaw danych oznaczonych etykietami, aby kierować klasyfikacją i wyodrębnianiem funkcji z większego zestawu danych bez etykiet.
Uczenie częściowo nadzorowane polega na szkoleniu modelu z minimalną ilością danych oznaczonych i dużą ilością danych nieoznaczonych.
W uczeniu wzmocnionym algorytm wzmacniający uczy się metodą prób i błędów, aby osiągnąć założony cel (uczenie przez wzmacnianie).
Mówiąc obrazowo, nieco metaforycznie, algorytm próbuje wielu różnych rzeczy i jest nagradzany lub karany w zależności od tego, czy jego zachowania pomagają, czy utrudniają osiągnięcie wyznaczonego celu.
Zazwyczaj uczenie się częściowo nadzorowane jest wybierane, gdy nabyte oznakowane dane wymagają wykwalifikowanych i odpowiednich zasobów w celu ich przeszkolenia i/lub nauczenia się na ich podstawie.
Warto przy tej okazji zauważyć i przypomnieć, że skuteczność Uczenia Maszynowego jest zależna od ilości danych oraz mocy obliczeniowych infrastruktury do tego wykorzystywanej.
Mimo tych ograniczeń, Machine Learning zapewnia wyniki:
- stosunkowo dokładne
- uzyskane stosunkowo szybko.
Gdzie wykorzystywany jest Machine Learning (Uczenie Maszynowe)?
Nim wskażemy pola, branże, sektory, problemy, w których Machine Learning znajduje najczęściej zastosowanie, tytułem wstępu powiedzmy tylko, że jest to koncepcja, technologia o korzeniach sięgających 1959 roku.
Wtedy to powstała bodaj pierwsza definicja sztucznej inteligencji stworzona przez Arthura Samuela.
Oczywiście współczesność Machine Learningu wygląda już o wiele bardziej zaawansowanie niż w swoich prapoczątkach.
Współczesne systemy uczą się bazując na ogromnych ilościach zróżnicowanych danych, a iteracyjny aspekt tej nauki pozwala im stale poprawiać jakość, trafność, wiarygodność wyników obliczeń.
Skuteczność i coraz większa doskonałość Machine Learningu sprawia, że Uczenie Maszynowe jest obecnie wykorzystywane w:
- wyszukiwarkach internetowych
- klientach poczty elektronicznej
- systemach rekomendacji (np. w e-Commerce, w silnikach rekomendacji platform VoD)
- aplikacjach dokonujących predykcji oraz rekomendacji inwestycyjnych
- aplikacjach szacujących ryzyko finansowe, kredytowe (np. scoring kredytowy)
- aplikacjach wykrywających, rozpoznających twarze, obiekty, ruch
- aplikacjach rozpoznających głos (np. asystenci głosowi)
- translatorach
- samochodach.
Generalnie rzecz ujmując, dzięki zastosowaniu wyrafinowanych metod statystycznych algorytmy Machine Learningowe są używane do:
- diagnozowania
- rozpoznawania
- prognozowania
- odkrywania prawidłowości, wzorców, reguł
- klasyfikowania
- identyfikowania
- wykrywania anomalii.
Biorąc pod uwagę branże, technologie Uczenia Maszynowego najczęściej są używane w:
- administracji
- bioinformatyce
- e-Commerce
- farmaceutyce
- marketingu (np. marketingu politycznym)
- medycynie i zdrowiu publicznym
- opiece zdrowotnej
- produkcji opartej na paliwach kopalnych
- transporcie
- usługach finansowych.
Zakres zastosowania Machine Learningu stale ulega poszerzeniu, stąd też powyższa lista będzie z czasem wymagała aktualizacji.
Z pewnością można powiedzieć, że Machine Learning ma przed sobą naprawdę obiecującą przyszłość, czego najlepszym dowodem są stałe inwestycje dużych graczy w tę technologię.
Jak podaje serwis Motley Fool w artykule pt. „Investing in Machine Learning Stocks”, globalne wydatki, inwestycje w Machine Learning do 2025 roku mają sięgać 100 miliardów dolarów, co daje roczną stopę zwrotu na poziomie 40%.
Wdrażanie rozwiązań z zakresu Machine Learningu, wykorzystanie modeli Uczenia Maszynowego staje się powoli koniecznością i bardzo silnym trendem, który wytwarza rodzaj rynkowej presji. Już dziś wiele biznesów jest opartych na uczeniu maszynowym.
Warto mieć zatem w pamięci zadania z artykułu pt. „Why You Should Invest In Machine Learning”, w którym czytamy, że organizacje są dziś wręcz zmuszone do podążania za tym trendem technologicznym.
Bycie nawet o krok dalej jest niezbędne, by oferować lepszy User Experience dla naszych klientów.
Machine Learning pozwala także bardziej efektywnie wykorzystywać zasoby, świadczyć usługi.
Warto także pamiętać, że Machine Learning pozwala organizacjom:
- tworzyć modele szybciej, o wiele bardziej precyzyjnie, w pełni automatycznie
- analizować większą ilość danych, o bardziej złożonych strukturach
- otrzymywać wyniki dokładniejsze, o wiele bardziej użyteczne
- identyfikować okazje, ryzyka, potencjały, zagrożenia
- automatyzować rutynowe działania, dzięki czemu możliwe są większe oszczędności, większa wydajność
- podejmować decyzje bardziej racjonalnie, trafne, dochodowe, zapewniające większy zysk.
Najlepszy język programowania do Uczenia Maszynowego?
Pisząc o Machine Learningu, algorytmach, które wspierają rozwój biznesów nie sposób nie poruszyć tematu najbardziej adekwatnego języka programowania, który jest rekomendowany do tworzenia aplikacji Machine Learningowych.
W artykule pt. „7 Top Machine Learning Programming Languages”, opublikowanym na blogu Code Academy,
Python jest jednym z najważniejszych języków programowania rekomendowanych przez autorów tekstu do tworzenia aplikacji Machine Learningowych.
Pozostałe sześć to:
- R
- C++
- Java
- JavaScript
- Go.
Dlaczego Python jest językiem pierwszego wyboru w takich zadaniach?
Jego najważniejszymi zaletami są przede wszystkim:
- prosta składnia
- czytelność
- elastyczność
- dostępność licznych bibliotek i frameworków (np. OpenCV, TensorFlow, PyTorch, NumPy, SciPy).
Ponadto, Python znacząco ułatwia wdrożenie, implementację złożonych koncepcji takich jak rachunek różniczkowy, czy algebra liniowa. A to jeszcze nie koniec.
Kolejną zaletą Pythona jest możliwość elastycznego wyboru między programowaniem obiektowym a skryptowym. Python nie wymaga także kompilowania, wprowadzane zmiany są widoczne natychmiastowo.
Python z dużą łatwością da się połączyć także z innymi językami programowania, dzięki czemu możliwe jest tworzenie pożądanych funkcjonalności.
Nie można także zapomnieć o uniwersalności Pythona, który może działać na dowolnej platformie (np. Windows, MacOS, Linux).
Czym jest Uczenie Maszynowe (Machine Learning)? Podsumowanie artykułu
- Jaka jest różnica pomiędzy sztuczną inteligencją a uczeniem maszynowym? Uczenie Maszynowe dla programistów jest pojęciem węższym i stanowi część sztucznej inteligencji (Artificial Intelligence).
- Machine Learning i Artificial Intelligence nie stanowią synonimów. AI Machine Learning nie jest pojęciem w sensie ścisłym poprawnym.
- Deep learning vs machine learning - choć zbliżone znaczeniowo nie stanowią synonimów.
- Sztuczna Inteligencja jest nauką o naśladowaniu ludzkich zdolności uczenia, przetwarzania informacji, poznawania, kategoryzowania danych oraz rozwiązywania problemów.
- Uczenie Maszynowe koncentruje się na tworzeniu algorytmów, wykorzystaniu danych, które mają nauczyć maszynę uczenia się.
- Machine Learning polega na udostępnieniu danych algorytmom, dzięki czemu mają one możliwość uczenia się, doskonalenia w sposób automatyczny oraz samodzielny (modele uczenia maszynowego).
- Podstawowym założeniem Uczenia Maszynowego jest to, że algorytmy potrafią samodzielnie się uczyć i robią to w sposób zbliżony do sposobu nauki człowieka.
- Na gruncie Machine Learning nauka jest rozumiana jako zdolność do identyfikacji wzorców oraz podejmowania decyzji z ograniczoną interwencją człowieka.
- W toku rozwoju Uczenia Maszynowego zauważono, że prawie każde zadanie, które można wykonać za pomocą wzorca zdefiniowanego na podstawie danych lub zestawu reguł, można zautomatyzować za pomocą uczenia maszynowego.
- W ramach Machine Learningu wykorzystywane są 4 metody nauki.
- W uczeniu nadzorowanym dane są oznaczone etykietami, aby dokładnie powiedzieć maszynie, jakich wzorców powinna szukać.
- W uczeniu nienadzorowanym algorytm próbuje nauczyć się pewnej nieodłącznej struktury danych za pomocą tylko nieoznaczonych przykładów.
- W uczeniu częściowo nadzorowanym w toku nauki algorytm wykorzystuje mniejszy zestaw danych oznaczonych etykietami, aby kierować klasyfikacją i wyodrębnianiem funkcji z większego zestawu danych bez etykiet.
- W uczeniu wzmocnionym algorytm wzmacniający uczy się metodą prób i błędów, aby osiągnąć założony cel.
- Skuteczność Uczenia Maszynowego jest w dużym stopniu uwarunkowana ilością danych oraz mocą obliczeniową komputerów.
- Uczenie Maszynowe jest najczęściej używane w wyszukiwarkach internetowych, systemach rekomendacji, aplikacjach dokonujących predykcji oraz rekomendacji inwestycyjnych, aplikacjach szacujących ryzyko kredytowe, wykrywających, rozpoznających twarze, obiekty, ruch, rozpoznających głos, translatorach oraz w samochodach autonomicznych.
- Algorytmy Machine Learningowe są używane do diagnozowania, rozpoznawania, prognozowania, odkrywania prawidłowości, wzorców, reguł, klasyfikowania, identyfikowania, wykrywania anomalii.
- Machine Learning w biznesie (generalnie uczenie maszynowe i sieci neuronowe, automatyzacja procesów) pozwala analizować większą ilość danych, o bardziej złożonych strukturach, identyfikować okazje, ryzyka, potencjały, zagrożenia, automatyzować rutynowe działania, procesy, podejmować decyzje bardziej racjonalnie, trafne, dochodowe, zapewniające większy zysk.
- Zastosowanie uczenia maszynowego, algorytm uczenia coraz częściej jest wykorzystywany do automatyzacji procesów, wspierania funkcjonalności takich jak mechanizmy rekomendacji, tworzenia nowych usług np. chatbotów, udzielających szczegółowych informacji, obsługujących klientów w czasie rzeczywistym.
- Python jest językiem programowania rekomendowanym do tworzenia aplikacji Machine Learningowych (Machine Learning Python).
- Python jest językiem uniwersalnym, elastycznym, klarownym, posiadającym liczne biblioteki oraz frameworki ułatwiające tworzenie aplikacji Machine Learningowych.
- Proces uczenia maszynowego, dokładność uczenia, analiza danych, eksploracja danych, sieć neuronowa, rozpoznawanie wzorów, Machine Learning automation to pojęcia, które nie są tylko abstrakcjami, ale coraz częściej znajdują zastosowanie w codziennym życiu, w postaci produktów cyfrowych opartych na modelu Uczenia Maszynowego.




