
Das Verhältnis zwischen der notwendigen und gleichzeitig ausreichenden Anzahl von Befragten und der Erkennbarkeit von Usability-Problemen hat lange Zeit verständliche Emotionen geweckt.
Wie Jakob Nielsen selbst vor mehr als zwanzig Jahren schrieb:
"Aufwendige Usability-Tests sind eine Verschwendung von Ressourcen. Die besten Ergebnisse erzielen Sie, wenn Sie nicht mehr als 5 Benutzer testen und so viele kleine Tests durchführen, wie Sie sich leisten können."
Es wäre unangemessen, einem Mann, der ein Vorläufer der Benutzererfahrung ist, nicht zu glauben, dass er einen sehr nüchternen und pragmatischen Ansatz hat und nützliche Skepsis und Vorsicht an den Tag legt.
Der Ansatz von Nielsen, der lange Zeit als Gewissheit in der UX galt, hat skeptische und teilweise offen kritische Haltungen erfahren.
Wenn Sie also, liebe Leserin, lieber Leser, Jakob Nielsens Aussagen über den Glauben und die Notwendigkeit von Argumenten, Vor- und Nachteile, nicht hinnehmen wollen, dann lesen Sie diesen Artikel.
Wir werden die Argumente der Befürworter von Usability-Tests mit nur 5 Befragten diskutieren und die Meinungen der Kritiker dieses Ansatzes näher beleuchten.
In den letzten Jahren sind kritische Stimmen laut geworden, und es lohnt sich, diese Argumentationslinie und Interpretation des Problems kennenzulernen.
Die intellektuelle Redlichkeit erfordert dies, und auch die Qualität der auf der Grundlage der Forschungsergebnisse getroffenen Entscheidungen hängt davon ab.
Da die Angelegenheit nicht so eindeutig zu sein scheint, wie Jakob Nielsen es gerne hätte, ist die Nachweisbarkeit des Problems und die Größe der Stichprobe eine Beziehung, die es wert ist, untersucht zu werden.
Nachdem Sie sich mit beiden Standpunkten vertraut gemacht haben, können Sie entscheiden, welchen Sie bevorzugen und welcher für ein bestimmtes Forschungsproblem oder -design am vorteilhaftesten ist.
Sind also fünf Benutzer, Befragte genug, um sicher zu bestimmen, ob die Forschung zuverlässige Ergebnisse geliefert hat, die es Ihnen ermöglichen, die optimalen Designentscheidungen zu treffen?
Wenn fünf Benutzer nicht ausreichen, warum ist das so?
Welche Mindestanzahl von Befragten sollte berücksichtigt werden, um die erwarteten Ergebnisse bei der Durchführung eines Website-Benutzertests zu erhalten?
Ist die Zahl der Befragten auf den Zweck der Untersuchung zugeschnitten? Handelt es sich um Sonderfälle oder um einen Forschungsstandard? — Das sind unsere Fragen.
Wir laden Sie herzlich ein, den Artikel zu lesen!
Benutzertests, Usability-Tests oder eine kurze Diskussion über die UX-Forschung
In den meisten Fällen werden Usability-Tests (z. B. für eine Website), Usability-Tests und UX-Forschung mit quantitativen, qualitativen oder gemischten Methoden durchgeführt.
UX-Forschung und Usability-Tests mit Benutzern und Vertretern der Zielgruppe werden in der Regel stationär oder aus der Ferne durchgeführt. Sie können moderiert oder unmoderiert sein.

Es gibt mindestens ein Dutzend Forschungsmethoden, die Ihnen bei der Durchführung eines Benutzertests helfen können.
In der Matrix, die durch die Achsen qualitative Forschung vs. quantitative Forschung, Verhaltensforschung (was Menschen tun) vs. Einstellungsforschung (was Menschen sagen) definiert wird, finden sich jedoch oft etwa neun der beliebtesten Methoden.
Wir erwähnen dies, weil man das Problem der Anzahl der Befragten nicht vom Gegenstand der Studie oder ihrer Methode trennen sollte.
Es lohnt sich auch, daran zu denken, dass die Ergebnisse des Tests, unabhängig davon, ob Sie sich auf quantitative Forschung, qualitative Forschung, Verhaltensforschung oder Einstellungsforschung beziehen, dazu dienen sollten, das Bestmögliche zu erreichen:
- Design-Entscheidungen
- Unternehmerische Entscheidungen
- Strategische Entscheidungen, die die Wettbewerbsfähigkeit des digitalen Produkts bestimmen
Die Ergebnisse der Tests, der Forschung und der beobachteten Reaktionen der Benutzer liefern spezifische Informationen, die es Ihnen ermöglichen, die Website zu verbessern und zu optimieren und sie intuitiver zu gestalten.
Mehr oder weniger erfolgreich.
Elemente wie das Forschungsszenario, der Verlauf der Studie, die Forschungsfragen sowie die Leitfragen in den Interviews mit den Benutzern (die es Ihnen ermöglichen, spezifischere Informationen zu erhalten), die Bedingungen, der Kontext der durchgeführten Forschung, die Forschungsinstrumente und die Fähigkeit zur Beobachtung haben einen Einfluss auf die Ergebnisse und verringern oder erhöhen die Kontrolle über sie.
Testergebnisse (insbesondere Usability-Tests) sind eine Empfehlung für Änderungen. Wie Sie wissen, sind Veränderungen mit Risiken, Verantwortung, Budget, Zeit und vielen anderen Fragen verbunden.
Es ist allgemein bekannt, dass das Ziel der meisten Beteiligten, u. a. UX/UI-Designer, UX-Forscher und Geschäftsinhaber, darin besteht, in kurzer Zeit glaubwürdige Ergebnisse der Tests mit den Benutzern zu erzielen.
Mit minimalen Mitteln und Ressourcen.
Die Ökonomisierung (in finanzieller, zeitlicher und organisatorischer Hinsicht) des Forschungs-, Design-, Optimierungs- und Entwicklungsprozesses ist aus naheliegenden Gründen verständlich.
Aber ist dies immer ein gerechtfertigter und nützlicher Ansatz?
Benutzertests, an denen nur fünf Personen teilnehmen, scheinen diese Anforderungen ideal zu erfüllen.
Aus wirtschaftlichen und organisatorischen Gründen ist es schwer, der Versuchung zu widerstehen, Argumente zu ignorieren, die die größere Legitimität der Durchführung einer umfangreicheren Studie anerkennen.
Wie sieht das in der Praxis aus? Wer hat in diesem Streit recht?
Warum Sie nur mit 5 Benutzern testen sollten — der Ansatz von Jakob Nielsen von der NN Group
Die Haltung von Nielsen ist seit Jahrzehnten bekannt und wurde in den letzten 30 Jahren in geringem Umfang geändert.
Der Mitbegründer der NN Group verteidigt seinen Ansatz.
Seine Haltung wird durch die auf der Website seiner Muttergesellschaft veröffentlichten Artikel sehr gut veranschaulicht.
Wenn Sie sich mit den Originalen vertraut machen wollen, sollten Sie die folgenden Artikel lesen: "Why You Only Need to Test with 5 Users", dessen Autor Nielsen ist, und "A mathematical model of the finding of usability problems", geschrieben von Nielsen und Thomas K. Landauer, sowie "How Many Test Users in a Usability Study", "Quantitative Studies: How Many Users to Test?", ebenfalls von Nielsen.
Um Ihre Perspektive zu erweitern, sollten Sie auch den Artikel von Raluca Budiu von der NN Group lesen: "Why 5 Participants Are Okay in a Qualitative Study, but Not in a Quantitative One".
Mit einem solchen Textkorpus können wir die Hauptargumente zusammenfassen, die zur Verteidigung des Ansatzes der 5 Benutzer vorgebracht werden.
Nielsen ist vor allem ein Verfechter der Ökonomisierung der Forschung. Er hält den gegenteiligen Ansatz für verschwenderisch und damit unnötig und vor allem für ungerechtfertigt.
Zumindest hält er sie für unangemessen und fordert einen anderen Ansatz, aber darüber werden wir später schreiben.
Nielsen stützt seine Argumentation auf ein proprietäres Modell, das es erlaubt, die Abhängigkeit zwischen der Anzahl der für die Forschung notwendigen Personen und der Anzahl der Usability-Probleme mathematisch und damit objektiv, unparteiisch, messbar und präzise zu bestimmen.
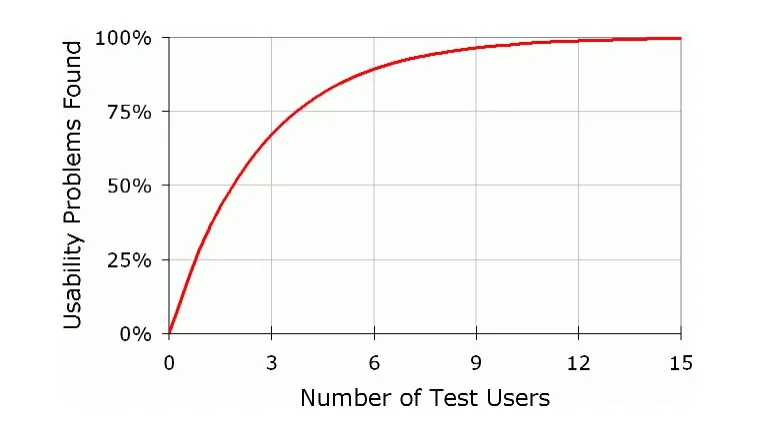
Nach dem Modell von Nielsen und Landauer — N (1-(1- L ) n ) — können 100 % der Probleme mit der Benutzerfreundlichkeit durch Studien mit 15 Benutzern aufgedeckt werden, und es werden nur 5 Befragte benötigt, um eine Entdeckungsrate von 85 % zu erreichen.
Es lohnt sich, Nielsen zu zitieren, der zu Recht darauf hinweist, dass bereits ein einziger Befragter Kenntnisse über Probleme mit der Nutzbarkeit in Höhe von 30 % liefern kann.
Mit jedem weiteren Benutzer steigt der Zuwachs an neuem Wissen und neu entdeckten Problemen nicht mehr so dynamisch an, da sich einige Probleme einfach überschneiden und verdoppeln. Nach dem fünften Benutzer erhalten Sie keine neuen Daten mehr.
Wie Nielsen feststellt:
"Wenn man immer mehr Benutzer hinzufügt, lernt man immer weniger, weil man immer wieder die gleichen Dinge sieht. Es gibt keinen wirklichen Grund, dasselbe mehrmals zu beobachten."
Warum bleibt Nielsen dann bei 5 und nicht bei 15 Befragten?
Denn er ist der Meinung, dass es effektiver ist, den Design- und Forschungsprozess zu wiederholen.
Laut Nielsen ist es besser, 85 % der Probleme zu erkennen als 100 %. Korrigieren Sie das Design und führen Sie die Untersuchung dann erneut durch. Wiederholen Sie den Vorgang. Anstatt eine Studie mit 15 Befragten durchzuführen, ist es besser, 3 Studien in 3 Phasen des Entwurfs, mit 5 Befragten in jeder Studie durchzuführen.
Nielsen ist überzeugt, dass ein solcher Ansatz es ermöglicht, das Problem des Forschungsschattens in Form von 15 % der Fragen zu beseitigen, deren Wichtigkeit und Bedeutung über Erfolg oder Misserfolg entscheiden können.
Seinem optimistischen Ansatz zufolge:
"Die zweite Studie mit 5 Benutzern wird die meisten der verbleibenden 15 % der ursprünglichen Nutzbarkeitsprobleme aufdecken, die in der ersten Testrunde nicht gefunden wurden".
"Sobald Sie Daten von einem einzigen Testnutzer gesammelt haben, schießen Ihre Erkenntnisse in die Höhe und Sie haben bereits fast ein Drittel aller Informationen über die Nutzbarkeit des Designs erfahren."
Der Ansatz von Nielsen — und er ist sich dessen bewusst, hält ihn aber nicht für so bedeutsam — ist gerechtfertigt, wenn die Zielgruppe homogen ist.
Wenn Sie es mit einigen Benutzergruppen zu tun haben und es in Wirklichkeit eine Norm ist. Sie müssen die ersten Tests mit den Vertretern der einzelnen Gruppen durchführen.
Zusammengefasst ist das Kardinalargument von Nielsen ein Argument, das sich nicht so sehr auf die Erkennung selbst bezieht, sondern auf ihre Auswirkungen, Gewinne und Verluste, die Fähigkeit, die Forschung zu optimieren und ihren Nutzen zu ökonomisieren.
Nielsen erklärt bei jeder Gelegenheit mit Nachdruck:
"Wenn man mit 5 Personen testet, findet man fast so viele Usability-Probleme wie mit viel mehr Testteilnehmern."
Gleichzeitig hat er im Laufe der Jahre seinen Ansatz korrigiert. Er machte sie kontextbezogener und stellte einen Zusammenhang zwischen der Anzahl der Befragten und der Art der Forschung und der Nachweisbarkeit her.
In seinem überarbeiteten Ansatz weist er auf Ausnahmen hin.
Nämlich:
- Für quantitative Forschung benötigen Sie mindestens 20 Benutzer
- Für die Kartensortierung — 15 Benutzer
- Für Eye-Tracking — 39 Benutzer
Während Nielsen die Argumente der Befürworter der größeren Zahl von Befragten zurückweist, weist er auf das Hauptargument hin, nämlich die Kapitalrendite, und überhöht es etwas.
Der Artikel von Raluca Budiu ist eine gute Zusammenfassung von Nielsens Ansatz. Budiu präsentierte in komprimierter Form drei entscheidende Argumente, die jeden davon überzeugen sollten, eine Forschung mit 5 Benutzern durchzuführen.
Diese 3 Hauptargumente sind:
- Qualitative Forschung und Tests mit Benutzern dienen nicht dazu, vorherzusagen, wie viele Leute Probleme mit der Nutzbarkeit einer Website haben werden, sondern sie werden verwendet, um die Probleme mit der Nutzbarkeit zu identifizieren.
- Das einmalige Auftreten eines Problems erfordert keine quantitative Bestätigung — ein Problem einer Person ist ein Problem für alle.
- Die Wahrscheinlichkeit, dass jemand auf ein Problem stößt, liegt bei 31 %.
Dies wirft natürlich das Problem der statistischen und gleichzeitig wirtschaftlichen Bedeutung solcher Entdeckungen auf, dessen sich der Autor bewusst ist.
Ein Problem, das sich in 1000 Fällen bei 1000 Website-Benutzern wiederholt und nicht nur einmal in 1000 Fällen, ist natürlich kritischer und potenziell schädlicher.
Die Ermittlung dieser Beziehung erfordert natürlich den Einsatz quantitativer Methoden, was Badiu nicht leugnet, aber auch nicht für notwendig hält, wobei sie wiederum auf die Verschwendung und Ökonomisierung der Forschung verweist.
Ist dies der richtige Ansatz? Lassen Sie uns nun den Kritikern das Wort erteilen.
Es reicht nicht aus, mit 5 Benutzern zu testen — ein kritischer Blick auf das Modell von Jakob Nielsen
Jakob Nielsen ist nicht unfehlbar, und jede substanzielle Kritik unterstützt die Wissensentwicklung und ermöglicht es Ihnen, bewusster und mit einem tieferen Verständnis der Konsequenzen zu wählen. Es ermöglicht Ihnen, eine Gewinn- und Verlustrechnung zu erstellen.
Was den kritischen Ansatz anbelangt, so können wir auch einen Korpus von Texten verschiedener Autoren präsentieren, und wir möchten Sie herzlich ermutigen, sich mit den Originalartikeln vertraut zu machen.
Es lohnt sich vor allem, die folgenden Artikel zu lesen: "5 Reasons You Should and Should Not Test With 5 Users" von Jeff Sauro und "Five, ten, or twenty-five. How many test participants?" von Ellen Francik und "The 5 User Sample Size myth: How many users should you really test your UX with?" von Frank Spillers.
Die ersten beiden Texte haben einen eher akademischen Charakter. Die dritte ist aufgrund ihres Insider-Charakters wertvoll, da sie auf die praktischen Herausforderungen hinweist, die sich im Design- und Forschungsprozess häufen.
Die Einwände gegen das Testmodell, die von 5 Personen geäußert wurden, betreffen hauptsächlich die folgenden Punkte:
- Das Fehlen einer Rangfolge der festgestellten Probleme.
- Wenn man die Wiederholbarkeit von Problemen mit der Nutzbarkeit und ihre Bedeutung absolut setzt, müssen 85 % der von fünf Befragten festgestellten Fehler nicht die kritischsten Probleme aus Sicht der Benutzererfahrung, des Vertriebs, der Geschäftsprozesse oder der Strategie sein.
- "Empfindlichkeit" dieser Methode — fünf Befragte werden die meisten offensichtlichen Probleme entdecken, wenn das Problem mit der Nutzbarkeit auf mindestens 31 % aller Benutzer zutrifft.
- Für spezifischere Probleme ist eine größere Stichprobe erforderlich. Dabei ist zu bedenken, dass fünf Befragte nicht 85 % aller Probleme aufdecken, sondern nur 85 % der offensichtlichsten Probleme. Obwohl diese Probleme erheblich sind, bedeutet das nicht, dass die restlichen 15 % als weniger kritisch angesehen werden können.
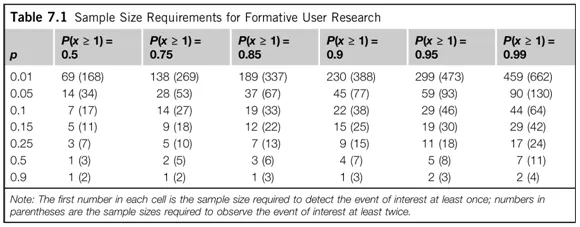
- Bei Tests, die den Prozentsatz der Befragten messen, die die Aufgabe gelöst haben, müssen Sie 80 Befragte testen, um ein statistisch korrektes Bild der Situation zu erhalten — Fehlermarge innerhalb von +/-10 %.
- Bei einer kleinen Stichprobe ist es schwieriger, die Nutzbarkeit einer Website zu bestimmen als ihre Unbrauchbarkeit. Mit anderen Worten: Die geringe Zahl der Befragten kann die Ergebnisse beeinflussen und die voreingenommenen Schlussfolgerungen und Bewertungen verstärken.
Ellen Francik lieferte interessante Argumente, die den Ansatz von Nielsen problematisch machen, indem sie Untersuchungen zitierte, die zeigen, dass die Nielsen-Kurve nicht immer wie eine Schweizer Uhr läuft.
Francik schreibt:
"Perfetti und Landesman (2001) testeten eine Online-Musikseite. Nach 5 Benutzern hatten sie nur 35 % aller Probleme mit der Nutzbarkeit gefunden.
Nach 18 Benutzern entdeckten sie immer noch schwerwiegende Probleme und hatten weniger als die Hälfte der geschätzten 600 Probleme aufgedeckt.
Spool und Schroeder (2001) berichteten auch über eine groß angelegte Website-Evaluierung, bei der 5 Teilnehmer nicht einmal annähernd 85 % der Probleme entdeckten".
Diese Diskrepanzen sind verständlich, wenn man bedenkt, wie unübersichtlich die Kategorie Forschung aus Sicht von Nielsen ist.
In erster Linie ist es nicht spezifisch.
Website-Usability-Tests mit Benutzern/Zielgruppen sind nie Forschung per se, sondern nur eine gezielte, fragmentierte und eingegrenzte Studie. Diese mythischen 85 % beziehen sich also nicht auf das Ganze, sondern meist auf ein Fragment. Keine Forschungsmethode würde es erlauben, das gesamte System zu untersuchen, aber das ist ein anderes Thema. Jeder lässt etwas aus, sieht es nicht, übertreibt oder abstrahiert.
Denken Sie daran, dass Forschungspraxis und Theorie zwei verschiedene Welten sind.
Und jede Studie über eine Zielgruppe hat ihre Grenzen in Bezug auf die folgenden Punkte:
- Zeit — umfangreiche Systeme können in der Regelstudienzeit nicht gründlich untersucht werden.
- Aufgaben — bei umfangreichen Systemen werden die am häufigsten gewählten Nutzungsszenarien und ausgewählten Funktionalitäten untersucht (UX-Forschung/Tests sind zielführend).
- Erkennbarkeit — die Erkennbarkeit von Fehlern nimmt mit der Anzahl und Vielfalt der möglichen Wege zur Erreichung einer bestimmten Aufgabe ab. Websites, auf denen eine bestimmte Aufgabe nur auf eine einzige, genau festgelegte Weise erledigt werden kann, sind selten.
- Die Verteilung der Entdeckung von häufigen, mäßig häufigen und seltenen Problemen ist proportional zum Stichprobenumfang.
Noch wichtiger ist, dass die Erkennbarkeit von Usability-Problemen nicht nur eine Frage der Anzahl der Befragten ist. Das ist eine sehr schädliche Reduktion und Vereinfachung.
Die folgenden Faktoren beeinflussen ebenfalls die Erkennbarkeit von Problemen mit der Nutzbarkeit:
- Die Anzahl und die Erfahrung der Forscher, die die Studie, die UX-Tests, die Usability-Tests der Website und die UX-Forschung korrekt durchführen können.
- Entwicklungsstadium des Entwurfs — je perfekter der Entwurf in Bezug auf die Nutzbarkeit ist, desto schwieriger ist die Erkennbarkeit von Problemen, und die Probleme selbst sind viel untypischer, subtiler und weniger offensichtlich.
- Erfahrung der Benutzer — je erfahrener die Benutzer sind, desto einfacher ist es für sie, das System für ihre Zwecke zu nutzen. Doch etwas Komplizierteres stellt für sie ein Problem dar.
- Von den Benutzern formulierte Problemdefinition — unterschiedliche Kompetenzen und Erfahrungen beeinflussen, was als Problem angesehen und welcher Stellenwert ihm beigemessen wird.
- Homogenität und Repräsentativität der Befragten.
- Die Komplexität einer Aufgabe, ihre Typizität.
- Dauer der Untersuchung und Anzahl der für die Studie geplanten Aufgaben — die Tendenz, Probleme zu erkennen oder zu ignorieren, hängt vom Grad der durch die Studie verursachten Ermüdung der Befragten ab.
Zu den oben genannten Fragen kommen noch rein praktische Probleme hinzu, die nicht mit dem idealen, modellhaften Bild der Forschung, sondern mit ihrem realen Verlauf zusammenhängen.
Das Problem der Auffindbarkeit hängt auch mit Folgendem zusammen:
- Die Qualität der Rekrutierung für die UX-Forschung
- Engagement in der UX-Forschung des Forschers selbst
- Tendenz, spezifischere Probleme beim Kategorisieren, Analysieren und Interpretieren von Daten zu vermeiden
- Organisatorische Herausforderungen — der iterative Ansatz von Nielsen für die UX-Forschung ist weitgehend ein idealistischer Ansatz, der in der Praxis auf viele Hindernisse stößt
Frank Spillers stellt eine aufschlussreiche und unverblümte rhetorische Frage:
"Bei 12 Benutzern würde man 4 Runden von Designänderungen und 4 Benutzertests durchführen. Zeigen Sie mir ein agiles Entwicklungsteam auf der Welt, das ein solches Ausmaß an Störungen und langwierigen Tests zulässt".
Er fügt in ähnlicher Weise hinzu:
"Selbst 3 kleinere Studien werden wahrscheinlich nicht den Realitäten der meisten Projekte gerecht".
Dies ist jedoch nicht das Ende der Gegenargumente gegen das Nielsen-Modell.
Der Ansatz von Nielsen wird auch aus folgenden Gründen kritisiert:
- Anachronismus — die Grundlage seines Modells wurde vor einigen Jahrzehnten formuliert, unter ganz anderen Bedingungen und in den frühen Stadien der Entwicklung der Benutzererfahrungsforschung.
- Schädlicher Universalismus — er berücksichtigt nicht die Besonderheiten der verschiedenen Zielgruppen, Kanäle und Geräte sowie die Unterschiede zwischen den Anwendungen (z. B. wird das Konzept einer Website nur minimal problematisiert).
- Die fehlende Berücksichtigung der Rollen, die die Benutzer bei der Nutzung der Website spielen, was sich erheblich auf den Umfang, die Anzahl, die Bedeutung und den Rang der von ihnen gemeldeten Probleme auswirkt.
- Die fehlende Einbeziehung der Sensibilität für das Problem der Befragten in der UX-Forschung — ein Usability-Problem ist nicht etwas, das jeden in gleicher Weise, im gleichen Sinn, Umfang und Gewicht betrifft.
Eine faszinierende und gleichzeitig zusammenfassende Darstellung aller Einwände gegen Nielsens Modell ist der Artikel "Beyond the five-user assumption: Benefits of increased sample sizes in usability testing", verfasst von Laura Faulkner, einer amerikanischen Autorin der University of Texas.
Faulkner verglich Tests mit einer unterschiedlichen Anzahl von Benutzern. Ihre Ergebnisse zeigen, dass ein erhebliches Risiko besteht, ungenaue Ergebnisse zu erhalten, wenn man sich zu sehr auf das Nielsen-Modell verlässt.
Bei einigen Tests mit 5 Befragten wurden Erkennungsraten von 99 % erreicht, bei anderen lag die Rate bei 55 %.
Durch die Verdoppelung des Stichprobenumfangs stieg der niedrigste Prozentsatz der von einem Satz aufgedeckten Probleme auf 80 % und auf 95 % bei 20 Benutzern.
Wie rekrutiert man Teilnehmer für Usability-Tests?
Da wir bereits die Vor- und Nachteile der Durchführung von Benutzertests mit 5 Benutzern erörtert haben, sollten wir zumindest kurz erwähnen, wie man Teilnehmer dafür rekrutiert.
Laut dem Artikel im Blog der Interaction Design Foundation "How to Recruit Users for Usability Studies" können Sie fünf Methoden zur Rekrutierung von Teilnehmern für Remote Usability-Tests oder persönliche Usability-Tests anwenden.
Und zwar die folgenden:
- Hallway- oder Guerilla-Tests — bei dieser Methode bitten Sie die Menschen in Ihrer Umgebung, sich Ihrer Testgruppe anzuschließen. Auch wenn es so aussieht, als wäre es ein einfacher Weg, "kostenlose Teilnehmer" zu gewinnen, spiegeln diese Personen höchstwahrscheinlich Ihre Zielgruppe nicht gut wider.
- Bestehende Benutzer — wenn Sie ein bereits bestehendes Produkt oder eine Dienstleistung testen möchten, ist die bereits vorhandene Benutzerbasis perfekt dafür geeignet. Auf diese Weise gewinnen Sie wertvolle Erkenntnisse und sammeln Daten, die für Ihr Produkt relevant sind.
- Online-Dienste für die Rekrutierung — die Interaction Design Foundation empfiehlt drei Online-Dienste, die Ihnen bei der Rekrutierung von Forschungsteilnehmern helfen können, darunter Craigslist, Usertesting.com und Amazon Mechanical Turk.
- Panel-Agenturen — sie verfügen über umfangreiche Datenbanken von Benutzern, die bereit sind, an Remote-Usability-Tests (unmoderiert) teilzunehmen, was Ihnen die Auswahl der richtigen Teilnehmer ermöglicht.
- Marktforschungsunternehmen — es ist die teuerste Methode der Rekrutierung, aber ein Unternehmen wird Ihnen bei der Auswahl der am besten geeigneten Teilnehmer sehr behilflich sein.
Wenn Sie mehr über die oben genannten Methoden erfahren möchten, empfehlen wir Ihnen, den genannten Artikel zu lesen, damit Sie die bestmögliche Testgruppe für Ihre Benutzertests zusammenstellen können.
Warum reicht es aus, 5 Benutzer zu testen? Zusammenfassung
- Laut Jakob Nielsen von der NN Group sind ausgedehnte Usability-Tests (z.B. eines Online-Shops) eine Verschwendung von Ressourcen.
- Nielsen unterstützt die Ökonomisierung der Forschung. Er ist der Meinung, dass die Ökonomisierung des Forschungs- und Gestaltungsprozesses aus offensichtlichen Gründen verständlich ist und als absoluter Wert angesehen werden sollte.
- Er hält die gegenteilige Vorgehensweise bei Tests mit den Benutzern für verschwenderisch und ungerechtfertigt.
- Nach dem Modell von Nielsen und Landauer, das 1993 entwickelt wurde, können 100 % der Usability-Probleme durch die Durchführung von Studien mit 15 Benutzern erkannt werden.
- Um eine 85 % Erkennbarkeit durch Tests mit Benutzern zu erreichen, benötigen Sie nur 5 Befragte.
- Wenn Sie weitere Testbenutzer hinzufügen, verdoppeln sich die entdeckten Nutzbarkeitsprobleme.
- Laut Jakob Nielsen ist es besser, statt einer Studie mit 15 Befragten drei Studien in drei Projektphasen mit jeweils fünf Befragten durchzuführen.
- Nielsens Argument bezieht sich nicht so sehr auf die Erkennung selbst, sondern auf deren Auswirkungen, Gewinne und Verluste sowie die Möglichkeit, die Forschung zu optimieren und ihren Nutzen zu optimieren.
- Die Argumente, die jeden davon überzeugen sollten, einen Test mit 5 Befragten durchzuführen, sind der Zweck der Untersuchung, nämlich die Identifizierung von Problemen, die Universalität des Problems — ein Problem für eine Person ist ein Problem für alle Menschen — und die Tatsache, dass die Wahrscheinlichkeit, dass jemand auf ein Problem stößt, bei 31 % liegt.
- Nielsens Ansatz wird in erster Linie kritisiert, unter anderem wegen des Anachronismus, des schädlichen Universalismus, der fehlenden Berücksichtigung der Rolle der Benutzer und der mangelnden Einbeziehung der Sensibilität für das Problem der Befragten.



