
Maschinelles Lernen ist eine Methode der Datenanalyse, die die automatische Erstellung von Analysemodellen beinhaltet.
Maschinelles Lernen geht davon aus, dass Algorithmen selbständig lernen können.
Lernen sollte in erster Linie als das Erkennen von Mustern und das Treffen von Entscheidungen mit begrenzter menschlicher Beteiligung verstanden werden.
Obwohl die obigen Definitionen bis zu einem gewissen Grad unkommunikativ erscheinen können, wird nach der Lektüre dieses Artikels alles, was darin abstrakt ist, einen viel konkreteren Charakter erhalten.
Was ist maschinelles Lernen? Wo kann maschinelles Lernen eingesetzt werden?
Warum ist maschinelles Lernen wichtig? Welche geschäftlichen Gründe sprechen für den Einsatz von Algorithmen des maschinellen Lernens?
Antworten auf diese und weitere Fragen finden Sie in diesem Artikel. Wie immer laden wir Sie herzlich ein, weiterzulesen!
Maschinelles Lernen — was ist das?
Die Frage, was maschinelles Lernen ist und wie es funktioniert, lässt sich beantworten, indem man erklärt, dass maschinelles Lernen ein Teil der Künstlichen Intelligenz (KI) ist.
Maschinelles Lernen zielt darauf ab, Daten mit Systemen zu teilen, dank derer sie automatisch und unabhängig lernen und sich verbessern können.
Das Wichtigste zuerst!
Lassen Sie uns zunächst die Terminologie, die wir in diesem Artikel verwenden werden, ein wenig ordnen. Maschinelles Lernen vs. Künstliche Intelligenz — das ist unser erstes Thema.
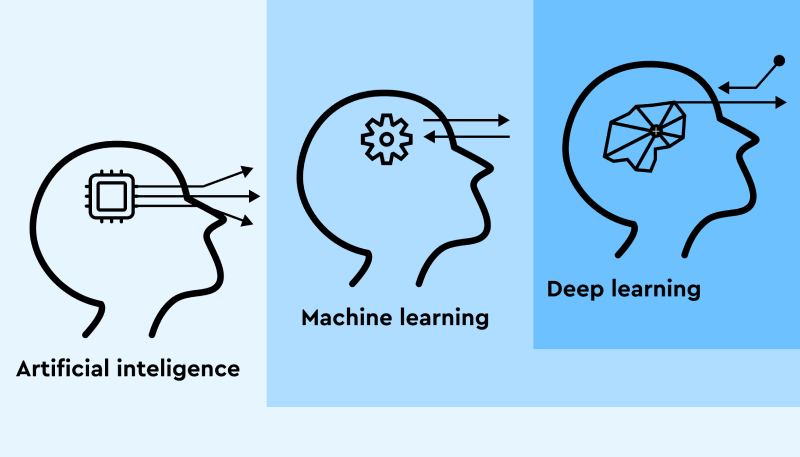
Maschinelles Lernen ist nicht dasselbe wie künstliche Intelligenz.
Diese Begriffe sind keine Synonyme und können nicht austauschbar verwendet werden, auch wenn dies in der Literatur zu diesem Thema manchmal geschieht.
Aus Gründen der Kohärenz sieht die Beziehung zwischen diesen Begriffen folgendermaßen aus:
- Künstliche Intelligenz (KI) — das ist der weiteste Begriff, der auch Konzepte von geringerer Tragweite umfasst.
- Maschinelles Lernen (ML) — ein engerer Begriff, der in der KI enthalten ist, aber nicht auf sie reduziert wird.
- Deep Learning (DL) — der Begriff mit dem engsten Anwendungsbereich, der ein Teil des maschinellen Lernens und der künstlichen Intelligenz ist.
Gibt es Unterschiede zwischen diesen Begriffen, Wissensgebieten und Technologien?
Künstliche Intelligenz ist im allgemeinsten Sinne eine Wissenschaft, die sich mit der Nachahmung der menschlichen Lernfähigkeit, der menschlichen Methoden des Lernens und der Informationsverarbeitung, der Kognition, der Kategorisierung von Daten und der Problemlösung beschäftigt.
Wie Sie in dem Artikel "Artificial Intelligence (AI) vs. Machine Learning (ML)" nachlesen können, verwendet ein Computersystem dank KI Mathematik und Logik, um eine Art des Denkens zu simulieren, die der Mensch zum Lernen verwendet.
Es geht darum, ständig neue Informationen hinzuzufügen und durch ständiges Lernen bessere, genauere, vorteilhaftere und effektivere Entscheidungen zu treffen.
Maschinelles Lernen ist ein spezieller Teilbereich der künstlichen Intelligenz. Ihr Ziel ist es, Algorithmen zu entwickeln, die einer Maschine das Lernen beibringen.
Mit anderen Worten: Maschinelles Lernen ist eine spezielle Anwendung der künstlichen Intelligenz.
Es ist der Prozess der Erstellung von Algorithmen unter Verwendung mathematischer Datenmodelle, die von direkten menschlichen Anweisungen unabhängig sind.
Maschinelles Lernen zielt also darauf ab, so selbstständig wie möglich zu lernen und auf der Grundlage früherer Erfahrungen Verbesserungen anzustreben.
Das Ziel von Spezialisten, die KI-Technologien entwickeln, besteht darin, Algorithmen zu schaffen, die es ermöglichen, Aufgaben auf eine Art und Weise auszuführen, die der menschlichen Denkweise so nahe wie möglich kommt, und Intelligenz ist ein wesentlicher Bestandteil davon.
Hinter der Idee des maschinellen Lernens steht die Überzeugung, dass Maschinen Zugang zu Daten haben sollten, damit sie selbständig lernen können.
Schließen wir die obigen Ausführungen mit einem Satz aus dem Artikel "How machine learning works", der auf dem Blog Algorithmia.com veröffentlicht wurde.
Und sie lautet wie folgt: "Nahezu jede Aufgabe, die mit einem durch Daten definierten Muster oder einer Reihe von Regeln erledigt werden kann, lässt sich mit maschinellem Lernen automatisieren."
Wir müssen zugeben, dass dies vielversprechend klingt, insbesondere aus wirtschaftlicher Sicht. Aber auch aus der Perspektive der Bedürfnisse der Benutzer von digitalen Produkten.
In der Praxis bedeutet dies die Möglichkeit, viele Prozesse zu automatisieren, die bisher von entsprechend ausgebildeten, vorbereiteten, aber oft müden, unengagierten und abgelenkten Menschen durchgeführt werden mussten.
Auch wenn der psychologische Aspekt nicht so wichtig erscheint, ist er doch erwähnenswert, denn Lösungen, die auf maschinellem Lernen basieren, sind frei von den typischen menschlichen Unzulänglichkeiten und Mängeln.
Denn in vielen Fällen haben Kontexte, Prozesse, Ziele und Bedürfnisse eine erhebliche Bedeutung.
Sie wirken sich auf die Effizienz, die Kostenwirksamkeit und die Wettbewerbsfähigkeit einer Organisation sowie auf den Grad der Zufriedenheit ihrer Kunden und Benutzer aus.
Stellen Sie sich zum Beispiel einen einfachen Kundenassistenten auf der Website eines Lieferunternehmens vor, der rund um die Uhr und an 365 Tagen im Jahr eine beliebige Anzahl von Kunden betreut, ihre (sehr typischen und sich wiederholenden) Fragen beantwortet und dabei nie müde oder frustriert wird oder ein Gefühl der Sinnlosigkeit verspürt.
Die beim maschinellen Lernen verwendeten Algorithmen sind bereits in der Lage, viele typische Kundenbedürfnisse zu erfüllen und, wie im obigen Beispiel, viele Fragen zu beantworten.
Welche Methoden werden beim maschinellen Lernen eingesetzt?
Beim maschinellen Lernen kommen verschiedene Methoden zum Einsatz, aber vier davon sind die beliebtesten. Und das sind:
- Überwachtes maschinelles Lernen
- Unüberwachtes maschinelles Lernen
- Teilüberwachtes Lernen
- Verstärkungslernen
Wie unterscheiden sie sich? Wir verweisen auf die Definitionen im Artikel "What is machine learning?", der im IBM-Blog veröffentlicht wurde und wesentlich zur Entwicklung des maschinellen Lernens beiträgt.
Beim überwachten maschinellen Lernen werden markierte Datensätze verwendet, um Algorithmen zu trainieren, die Daten klassifizieren oder Ergebnisse vorhersagen.
Wenn Eingabedaten in ein Modell einfließen, passt es seine Gewichte an, bis es passend ist.
Dies geschieht als Teil des Kreuzvalidierungsprozesses, der dazu beiträgt, eine Überanpassung oder Unteranpassung des Modells zu vermeiden.
Mit anderen Worten: Beim überwachten maschinellen Lernen werden die Daten mit Etiketten versehen, um der Maschine genau zu sagen, nach welchen Mustern sie suchen soll.
Beim unüberwachten maschinellen Lernen werden Algorithmen des maschinellen Lernens zur Analyse und Gruppierung von nicht beschrifteten Datensätzen verwendet.
Diese Algorithmen entdecken versteckte Muster oder Datengruppen, ohne dass ein menschliches Eingreifen erforderlich ist.
Unüberwachtes maschinelles Lernen wird verwendet, um Ähnlichkeiten und Unterschiede in Informationen zu finden, wodurch es eine perfekte Lösung für die Analyse von Sondierungsdaten, Cross-Selling-Strategien, Kundensegmentierung und das Erkennen von Bildern und Mustern darstellt.
Algorithmen für unüberwachtes maschinelles Lernen werden verwendet, wenn die zu lernenden Daten nicht klassifiziert oder gekennzeichnet sind.
Beim unüberwachten Lernen wird untersucht, wie Systeme aus unmarkierten Daten eine Funktion ableiten können, die eine verborgene Struktur beschreibt.
Das System legt die Eingabedaten nicht fest, sondern erforscht sie und kann aus den Datensätzen Schlussfolgerungen ziehen, um verborgene Strukturen aus unbeschrifteten Daten zu beschreiben.
Mit anderen Worten: Beim unüberwachten Lernen versucht der Algorithmus, eine bestimmte inhärente Datenstruktur nur durch unmarkierte Beispiele zu erlernen.
Die Daten sind nicht beschriftet, und die Aufgabe der Maschine ist es, alle Muster zu finden, die gefunden werden können.
Teilüberwachtes Lernen versucht, die Vorteile der oben genannten Methoden — überwachtes Lernen und unüberwachtes Lernen — zu kombinieren.
Im Laufe des Lernprozesses verwendet der Algorithmus einen kleineren beschrifteten Datensatz, um die Klassifizierung und Merkmalsextraktion aus einem größeren unbeschrifteten Datensatz zu steuern.
Beim teilüberwachten Lernen wird ein Modell mit einer minimalen Menge an gekennzeichneten Daten und einer großen Menge an nicht gekennzeichneten Daten trainiert.
Beim Verstärkungslernen lernt der Verstärkungsalgorithmus durch Versuch und Irrtum, das gewünschte Ziel zu erreichen (Lernen durch Verstärkung).
Bildlich gesprochen probiert der Algorithmus viele verschiedene Dinge aus und wird belohnt oder bestraft, je nachdem, ob sein Verhalten dem Erreichen des festgelegten Ziels dient oder es behindert.
In der Regel wird teilüberwachtes maschinelles Lernen gewählt, wenn die erworbenen markierten Daten qualifizierte und geeignete Ressourcen erfordern, um sie zu trainieren und/oder auf ihrer Grundlage zu lernen.
Es sei daran erinnert, dass die Effektivität des maschinellen Lernens von der Anzahl der Daten und der Rechenleistung der zu diesem Zweck verwendeten Infrastruktur abhängt.
Trotz dieser Einschränkungen gewährleistet das maschinelle Lernen, dass die Ergebnisse stimmen:
- Relativ genau
- Relativ schnell erworben
Wo wird maschinelles Lernen eingesetzt?
Bevor wir auf die Bereiche, Branchen, Sektoren und Probleme eingehen, in denen und für das maschinelle Lernen am häufigsten eingesetzt wird, möchten wir einleitend sagen, dass es sich um ein Konzept und eine Technologie handelt, deren Ursprünge auf das Jahr 1959 zurückgehen.
Damals wurde die erste Definition von künstlicher Intelligenz von Arthur Samuel erstellt.
Natürlich ist das maschinelle Lernen heute weiter fortgeschritten als in seinen Anfängen.
Moderne Systeme lernen auf der Grundlage enormer Mengen unterschiedlicher Daten, und der iterative Aspekt dieser Wissenschaft ermöglicht es ihnen, die Qualität, Genauigkeit und Glaubwürdigkeit der Ergebnisse kontinuierlich zu verbessern.
Die Effektivität und zunehmende Perfektion des maschinellen Lernens führen dazu, dass es in folgenden Bereichen eingesetzt wird:
- Internet-Browser
- E-Mail-Programme
- Empfehlungssysteme (z. B. im E-Commerce und Empfehlungsmaschinen von VoD-Plattformen)
- Anwendungen zur Durchführung von Prognosen und Investitionsempfehlungen
- Anwendungen zur Einschätzung von Finanz- und Kreditrisiken (z. B. Kreditwürdigkeitsprüfung)
- Anwendungen zur Erkennung von Gesichtern, Objekten oder Bewegungen
- Anwendungen, die Sprache erkennen (z. B. Sprachassistenten)
- Anwendungen für die Übersetzung
- Autos
Im Allgemeinen werden Algorithmen des maschinellen Lernens dank des Einsatzes ausgefeilter statistischer Methoden verwendet, um:
- Diagnose
- Erkennen
- Vorhersagen
- Regelmäßigkeiten, Muster, Regeln entdecken
- Klassifizieren
- Identifizieren
- Anomalien erkennen
Was die Branchen betrifft, so wird maschinelles Lernen am häufigsten in den folgenden Bereichen eingesetzt:
- Verwaltung
- Bioinformatik
- E-Commerce
- Pharmazie
- Marketing (z. B. politisches Marketing)
- Medizin und Gesundheitswesen
- Gesundheitswesen
- Produktion auf der Grundlage fossiler Brennstoffe
- Transport
- Finanzdienstleistungen
Der Anwendungsbereich des maschinellen Lernens erweitert sich ständig. Die obige Liste muss daher im Laufe der Zeit aktualisiert werden.
Wir können mit Zuversicht sagen, dass das maschinelle Lernen eine vielversprechende Zukunft vor sich hat, wie die kontinuierlichen Investitionen der großen Akteure in diese Technologie zeigen.
Laut Motley Fool, der in dem Artikel "Investing in Machine Learning Stocks" schreibt, sollen die weltweiten Ausgaben und Investitionen in Machine Learning bis 2025 100 Milliarden Dollar erreichen, was zu einer jährlichen Rendite von 40 % führt.
Die Implementierung von maschinellen Lernlösungen und die Verwendung von maschinellen Lernmodellen wird langsam zu einer Notwendigkeit und zu einem starken Trend, der Druck auf den Markt ausübt. Schon jetzt basieren viele Unternehmen auf maschinellem Lernen.
Daher lohnt es sich, die Sätze aus dem Artikel "Why You Should Invest In Machine Learning" im Hinterkopf zu behalten, in dem wir lesen können, dass Unternehmen heute fast gezwungen sind, diesem technologischen Trend zu folgen.
Auch nur einen Schritt voraus zu sein, ist wichtig, um unseren Kunden eine bessere Benutzererfahrung zu bieten.
Maschinelles Lernen hilft auch dabei, Ressourcen effizienter zu nutzen und Dienstleistungen anzubieten.
Es sollte auch daran erinnert werden, dass maschinelles Lernen Unternehmen in die Lage versetzt:
- Modelle schneller, präziser und vollautomatisch erstellen
- Analysieren Sie mehr Daten mit einer komplexeren Struktur
- Genauere und nützlichere Ergebnisse zu erhalten
- Identifizierung von Chancen, Potenzialen und Bedrohungen
- Automatisierung von Routineaufgaben, wodurch sich Einsparungen und Effizienz steigern lassen
- Rationalere, genauere und profitablere Entscheidungen treffen
Gibt es die beste Programmiersprache für maschinelles Lernen?
Wenn man über Algorithmen des maschinellen Lernens schreibt, die die Entwicklung von Unternehmen unterstützen, kommt man nicht umhin, das Thema einer geeigneten Programmiersprache anzusprechen, die für die Erstellung von Anwendungen des maschinellen Lernens empfohlen wird.
In dem Artikel "7 Top Machine Learning Programming Languages", der im Blog von Code Academy veröffentlicht wurde, ist Python eine der wichtigsten Programmiersprachen, die von den Autoren des Textes für die Erstellung von maschinellen Lernanwendungen empfohlen wird.
Die anderen sechs sind:
- R
- C++
- Java
- JavaScript
- Go
Warum ist Python die erste Wahl für solche Aufgaben?
Zu seinen Vorteilen gehören folgende:
- Einfache Syntax
- Klarheit
- Flexibilität
- Verfügbarkeit zahlreicher Bibliotheken und Frameworks (z. B. OpenCV, Tensor Flow, PyTorch, NumPy, SciPy)
Außerdem erleichtert Python die Anwendung und Umsetzung komplexer Konzepte wie Kalkül oder lineare Algebra erheblich. Aber das ist noch nicht das Ende.
Ein weiterer Vorteil von Python ist die Möglichkeit, flexibel zwischen objektorientierter Programmierung und Skripting zu wählen. Python muss auch nicht kompiliert werden; die eingegebenen Änderungen sind sofort sichtbar.
Python kann leicht mit anderen Programmiersprachen kombiniert werden, wodurch es möglich ist, die gewünschten Funktionalitäten zu erstellen.
Nicht zu vergessen ist auch die Universalität von Python, das auf jeder Plattform (z. B. Windows, MacOS, Linux) eingesetzt werden kann.
Maschinelles Lernen — was ist das? Zusammenfassung
- Was ist der Unterschied zwischen künstlicher Intelligenz und maschinellem Lernen? Maschinelles Lernen ist für Programmierer ein engerer Begriff und gehört zur Künstlichen Intelligenz.
- Maschinelles Lernen und künstliche Intelligenz sind keine Synonyme. KI, maschinelles Lernen, ist kein korrekter Begriff.
- Obwohl Deep Learning und maschinelles Lernen semantisch ähnlich sind, sind sie nicht synonym.
- Künstliche Intelligenz ist eine Wissenschaft, die sich mit der Nachahmung der menschlichen Lernfähigkeit, Informationsverarbeitung, Kognition, Kategorisierung von Daten und Problemlösung befasst.
- Beim maschinellen Lernen geht es um die Entwicklung von Algorithmen und die Verwendung von Daten, die einer Maschine das Lernen beibringen sollen.
- Beim maschinellen Lernen werden Daten mit Algorithmen geteilt, dank derer diese automatisch und unabhängig lernen und sich verbessern können (Modelle des maschinellen Lernens).
- Die Grundannahme des maschinellen Lernens ist, dass Algorithmen selbstständig lernen können, und zwar auf eine ähnliche Weise wie Menschen lernen.
- Im Bereich des maschinellen Lernens versteht man unter Wissenschaft die Fähigkeit, Muster zu erkennen und Entscheidungen zu treffen, ohne dass der Mensch eingreifen muss.
- Bei der Entwicklung des maschinellen Lernens wurde festgestellt, dass "fast jede Aufgabe, die mit einem datendefinierten Muster oder einer Reihe von Regeln erledigt werden kann, mit maschinellem Lernen automatisiert werden kann."
- Das maschinelle Lernen verwendet 4 Methoden zum Lernen.
- Beim überwachten maschinellen Lernen werden die Daten mit Etiketten versehen, um der Maschine genau zu sagen, nach welchen Mustern sie suchen soll.
- Beim unüberwachten Lernen versucht der Algorithmus, eine bestimmte inhärente Datenstruktur nur durch unmarkierte Beispiele zu lernen.
- Beim teilüberwachten Lernen verwendet der Algorithmus im Laufe des Lernprozesses einen kleineren beschrifteten Datensatz, um die Klassifizierung und Merkmalsextraktion aus einem größeren unbeschrifteten Datensatz zu steuern.
- Beim Verstärkungslernen lernt der Verstärkungsalgorithmus durch Versuch und Irrtum, das gewünschte Ziel zu erreichen.
- Die Effektivität des maschinellen Lernens hängt weitgehend von der Menge der Daten und der Rechenleistung ab.
- Maschinelles Lernen wird häufig in Internet-Browsern, Empfehlungssystemen, Anwendungen für Vorhersagen und Anlageempfehlungen, Anwendungen zur Einschätzung des Kreditrisikos, zur Erkennung von Gesichtern, Objekten, Bewegungen, Sprache, Übersetzungsanwendungen und autonomen Fahrzeugen eingesetzt.
- Algorithmen des maschinellen Lernens werden zur Diagnose, Erkennung, Vorhersage, Entdeckung von Regelmäßigkeiten, Mustern und Regeln sowie zur Klassifizierung, Identifizierung und Erkennung von Anomalien eingesetzt.
- Maschinelles Lernen in der Wirtschaft (neuronale Netze, Automatisierung von Prozessen) ermöglicht es, mehr Daten mit komplexeren Strukturen zu analysieren, Chancen, Risiken und potenzielle Bedrohungen zu erkennen, Routineaufgaben und -prozesse zu automatisieren und rationalere, genauere und profitablere Entscheidungen zu treffen.
- Algorithmen des maschinellen Lernens werden immer häufiger eingesetzt, um Prozesse zu automatisieren, Funktionalitäten wie Empfehlungsmechanismen zu unterstützen und neue Dienste zu schaffen, z. B. Chatbots, die detaillierte Informationen liefern und Kunden in Echtzeit bedienen.
- Python ist eine Programmiersprache, die für die Erstellung von Anwendungen für maschinelles Lernen empfohlen wird.
- Python ist universell, flexibel und übersichtlich und verfügt über zahlreiche Bibliotheken und Frameworks, die die Erstellung von maschinellen Lernanwendungen erleichtern.
- Der Prozess des maschinellen Lernens, die Genauigkeit des Lernens, die Datenanalyse, die Exploration von Daten, das neuronale Netz, die Mustererkennung und die Automatisierung des maschinellen Lernens sind Begriffe, die nicht nur abstrakt sind, sondern im täglichen Leben immer häufiger in digitalen Produkten verwendet werden, die auf Modellen des maschinellen Lernens basieren.




